Gemma 4 es la familia de modelos de inteligencia artificial open source de Google, lanzada el 2 de abril de 2026 con licencia Apache 2.0, capacidades multimodales (texto, imagen, audio y vídeo) y hasta 256K tokens de contexto. El 3 de junio de 2026 Google amplió la familia con Gemma 4 12B, un modelo multimodal unificado que procesa texto, imagen, audio y vídeo sin codificadores separados y funciona en un portátil con 16 GB de memoria. Si ya conoces el ecosistema de Google a través de nuestra biblioteca de prompts para Gemini, Gemma 4 representa la otra cara de la moneda: modelos que puedes descargar, ejecutar en tu propio hardware y modificar sin restricciones comerciales.
En esta guía analizamos las cinco variantes del modelo (incluido el nuevo 12B), sus benchmarks frente a la competencia, la arquitectura técnica que los diferencia, y una colección de prompts listos para copiar y pegar.
Qué es Gemma 4 y por qué importa
Gemma 4 es la familia de modelos abiertos de Google DeepMind, diseñada para razonamiento avanzado y flujos de trabajo agénticos. A diferencia de Gemini, que es el modelo propietario accesible solo a través de la API de Google, Gemma 4 ofrece pesos abiertos que cualquier desarrollador o empresa puede descargar, ejecutar localmente y adaptar a sus necesidades.
El cambio más significativo respecto a versiones anteriores es la licencia. Gemma 3 se distribuía bajo la Gemini Community License, que imponía restricciones de uso comercial para empresas con más de un millón de usuarios mensuales. Gemma 4 adopta la licencia Apache 2.0, la más permisiva del ecosistema open source. Esto significa uso comercial sin restricciones, modificación libre y redistribución sin condiciones adicionales.
Google define esta generación con una frase directa: "Byte for byte, the most capable open models". Los datos respaldan esa afirmación, como veremos en la sección de benchmarks.
Otras novedades destacadas de Gemma 4:
- Multimodalidad nativa: procesamiento de texto, imagen, audio y vídeo en un mismo modelo.
- Soporte para más de 140 idiomas, incluido el español.
- Contexto de hasta 256K tokens en las variantes más grandes, suficiente para analizar documentos extensos o codebases completos.
- Llamada a funciones nativa (function calling), lo que permite construir agentes autónomos sin wrappers adicionales.
Las 5 variantes de Gemma 4
Google ha lanzado Gemma 4 en cinco tamaños distintos, cada uno optimizado para un escenario de uso diferente. La decisión de cuál usar depende del hardware disponible y del equilibrio entre rendimiento y coste computacional.
| Variante | Parámetros totales | Parámetros activos | Contexto | Arquitectura | Mejor para |
|---|---|---|---|---|---|
| E2B | 2.300M | 2.300M | 128K tokens | Dense | Dispositivos edge, móvil, IoT |
| E4B | 4.500M | 4.500M | 128K tokens | Dense | Apps móviles con razonamiento |
| 12B Unified | 11.950M | 11.950M | 256K tokens | Dense, multimodal sin codificadores | Portátiles de 16 GB, multimodal local |
| 26B A4B | 26.000M | 3.800M | 256K tokens | Mixture of Experts | Portátiles, coste optimizado |
| 31B Dense | 30.700M | 30.700M | 256K tokens | Dense | Máximo rendimiento, investigación |
E2B y E4B, para el edge
Las variantes E2B (2.3B) y E4B (4.5B) están pensadas para ejecutarse en dispositivos con recursos limitados. Un Raspberry Pi o un smartphone moderno puede cargar E2B sin problemas. Ambas incluyen soporte nativo de audio a través de un codificador conformer tipo USM, algo que no existía en Gemma 3.
12B Unified, el nuevo multimodal para portátiles
Lanzada el 3 de junio de 2026, la variante 12B es la novedad más reciente de la familia y la primera de tamaño medio con entrada de audio nativa. Su rasgo distintivo es la arquitectura unificada sin codificadores (encoder-free): en lugar de pasar imagen y audio por redes codificadoras separadas, alimenta los datos multimodales directamente al transformer principal, el mismo esqueleto decoder-only que usa la variante 31B Dense. El embedder de visión ocupa solo 35 millones de parámetros y sustituye a las 27 capas de vision transformer de los enfoques tradicionales.
En la práctica esto significa que un único modelo de 11.950 millones de parámetros entiende texto, imágenes, audio en crudo a 16 kHz y vídeo a 1 fotograma por segundo, y cabe en un portátil con GPU de 16 GB de VRAM o memoria unificada. Google lo posiciona para reconocimiento de voz, diarización, comprensión de vídeo, razonamiento agéntico y programación, todo en local y sin enviar datos a la nube. Ese control sobre los datos es el mismo motivo por el que muchas empresas europeas están revisando qué asistente de IA usan; lo analizamos en detalle en nuestra guía de alternativas europeas a ChatGPT.
26B A4B, el equilibrio inteligente
Esta es quizá la variante más interesante de Gemma 4. Utiliza una arquitectura Mixture of Experts (MoE) con 26.000 millones de parámetros totales, pero solo 3.800 millones activos en cada inferencia. El resultado es un modelo que compite con otros de 20 veces su tamaño en parámetros activos. En el ranking LM Arena Chat, esta variante alcanza la posición #6 global con apenas 3.8B de parámetros activos.
31B Dense, máxima potencia
La variante de 31.000 millones de parámetros densos ofrece el mejor rendimiento absoluto de la familia. Ocupa la posición #3 en LM Arena Chat (texto) con una puntuación de aproximadamente 1452 Elo. Requiere una GPU con al menos 24 GB de VRAM para ejecutarse de forma fluida.
Benchmarks y rendimiento
Los benchmarks publicados por Google sitúan a Gemma 4 como el modelo open source de referencia en su franja de parámetros. Todos los datos proceden de la ficha técnica oficial de Gemma 4, actualizada el 3 de junio de 2026 con la incorporación de la variante 12B.
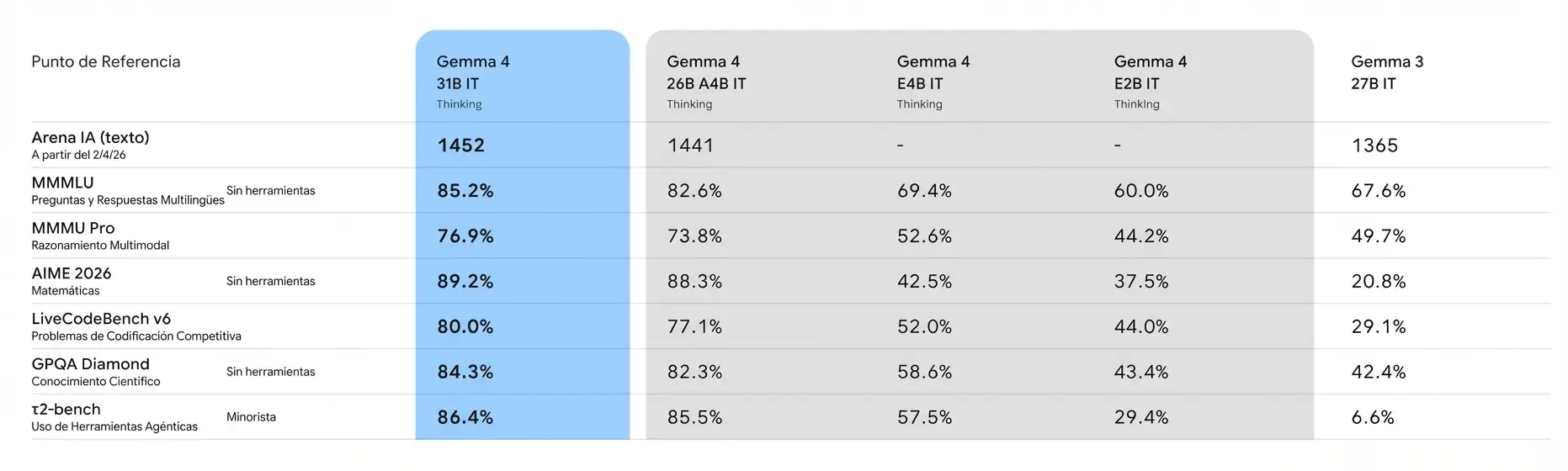
Benchmarks oficiales del lanzamiento de Gemma 4 en abril de 2026; la tabla inferior añade la variante 12B de junio (fuente: Google DeepMind)
| Benchmark | Gemma 4 31B | Gemma 4 26B A4B | Gemma 4 12B | Gemma 4 E4B | Gemma 4 E2B | Gemma 3 27B |
|---|---|---|---|---|---|---|
| Arena IA (texto, Elo) | 1452 | 1441 | — | — | — | 1365 |
| MMMLU (multilingüe) | 85,2% | 82,6% | 83,4% | 69,4% | 60,0% | 67,6% |
| MMMU Pro (razonamiento multimodal) | 76,9% | 73,8% | 69,1% | 52,6% | 44,2% | 49,7% |
| AIME 2026 (matemáticas) | 89,2% | 88,3% | 77,5% | 42,5% | 37,5% | 20,8% |
| LiveCodeBench v6 (programación) | 80,0% | 77,1% | 72,0% | 52,0% | 44,0% | 29,1% |
| GPQA Diamond (conocimiento científico) | 84,3% | 82,3% | 78,8% | 58,6% | 43,4% | 42,4% |
| τ2-bench (herramientas agénticas) | 86,4% | 85,5% | 69,0% | 57,5% | 29,4% | 6,6% |
El salto respecto a Gemma 3 27B es notable en todas las métricas. En AIME 2026 (problemas matemáticos de competición), Gemma 4 31B pasa del 20,8% al 89,2%. En programación (LiveCodeBench v6), la mejora va del 29,1% al 80,0%. Quizá el dato más impactante es τ2-bench (uso de herramientas agénticas), donde Gemma 3 27B apenas alcanzaba un 6,6% y Gemma 4 31B llega al 86,4%.
La nueva variante 12B merece una lectura aparte. En MMMLU multilingüe (83,4%) supera incluso a la 26B A4B, y en el resto de métricas se queda a pocos puntos de modelos que necesitan bastante más memoria, con la ventaja añadida de ser totalmente multimodal en un portátil de 16 GB. Para quien busque el equilibrio entre capacidad y hardware accesible, hoy es la opción más interesante de la familia.
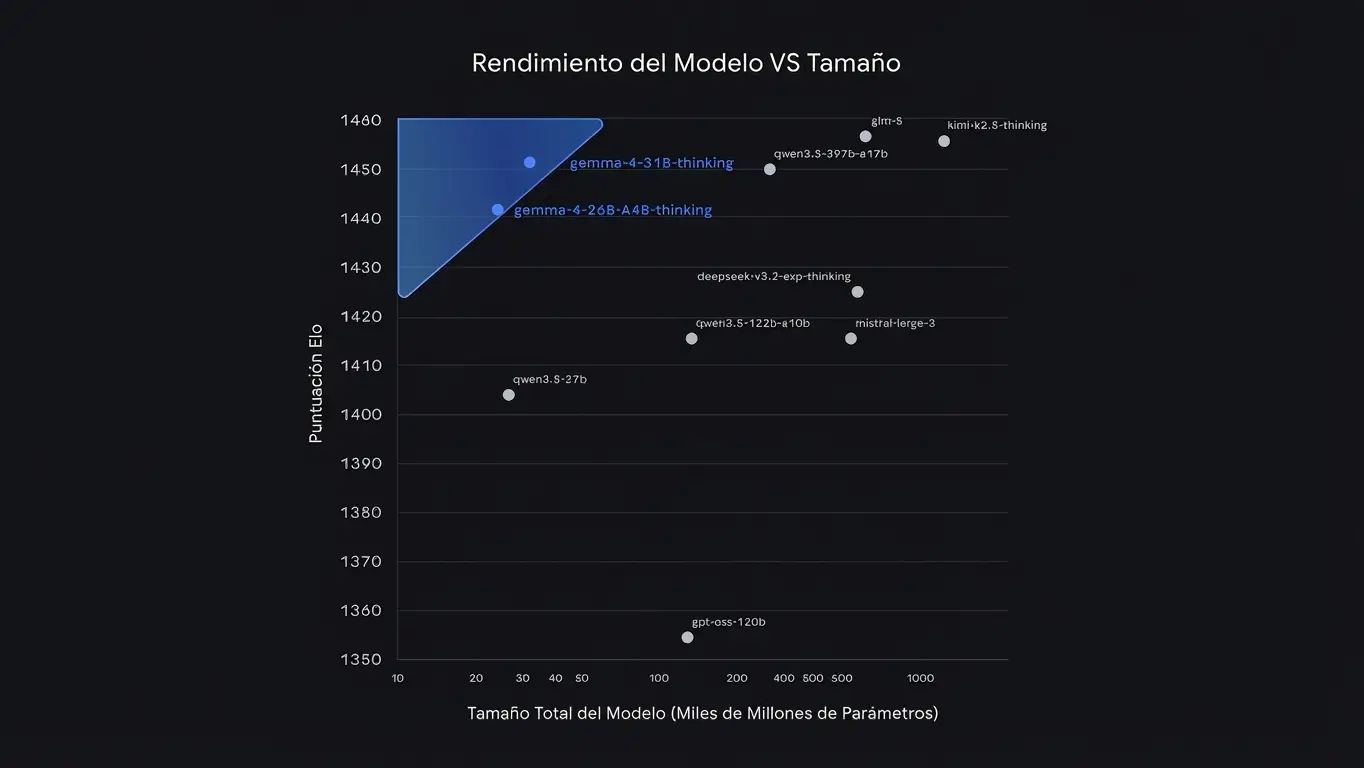
Rendimiento del modelo vs tamaño. Gemma 4 domina la esquina superior izquierda: máximo rendimiento con mínimo tamaño (fuente: Google DeepMind)
El gráfico anterior ilustra la eficiencia de Gemma 4. Tanto la variante 31B como la 26B A4B se sitúan en la esquina superior izquierda, lo que significa máximo rendimiento Elo con un tamaño de modelo relativamente pequeño. Modelos como DeepSeek V3, Qwen 3.5 397B o Mistral Large 3 necesitan entre 10x y 30x más parámetros para alcanzar puntuaciones similares.
La variante MoE (26B A4B) resulta especialmente competitiva, porque logra resultados cercanos al modelo denso de 31B con una fracción del coste computacional.
Prueba estos prompts con Gemma 4, Gemini y más modelos
ilisai te da acceso a modelos de Google y otros proveedores en una sola plataforma. Investigación con IA, generación de imágenes con Nano Banana Pro y modelos desplegados en servidores europeos.
Sin tarjeta · Plan gratuito disponible
Arquitectura y novedades técnicas
Gemma 4 introduce varias innovaciones arquitectónicas que explican su rendimiento superior con menos parámetros.
Atención híbrida
En lugar de usar atención global pura (costosa para secuencias largas), Gemma 4 combina dos mecanismos. Las capas con atención local utilizan una ventana deslizante de 512 a 1024 tokens, procesando el contexto inmediato con eficiencia. Las capas con atención global operan sobre la secuencia completa, proporcionando conciencia del contexto total. El modelo alterna entre ambos tipos según la capa, lo que reduce el consumo de memoria sin sacrificar la capacidad de comprender documentos largos.
Dual RoPE y Per-Layer Embeddings
Gemma 4 utiliza dos variantes de codificación posicional rotativa (RoPE). Las capas de atención local usan RoPE estándar, mientras que las globales emplean RoPE proporcional. Además, introduce Per-Layer Embeddings (PLE), una segunda tabla de embeddings que condiciona cada capa de forma individual. Estas decisiones mejoran la capacidad del modelo para distinguir posiciones relativas en documentos muy largos.
Mixture of Experts en la variante 26B
La variante 26B A4B utiliza una arquitectura MoE donde solo un subconjunto de los parámetros se activa para cada token. Con 3.800 millones de parámetros activos por inferencia sobre un total de 26.000 millones, esta arquitectura consigue un rendimiento cercano al modelo denso de 31B con un coste computacional dramáticamente menor.
Modo de razonamiento (Thinking Mode)
Gemma 4 incorpora un modo de razonamiento explícito que se activa con el token <|think|> al inicio del prompt del sistema. Cuando está activo, el modelo genera un proceso de razonamiento interno antes de producir la respuesta final.
<|think|>
[El modelo desarrolla su razonamiento paso a paso aquí]
[Evalúa alternativas y verifica su lógica]
</|think|>
[Respuesta final concisa y fundamentada]Esta funcionalidad es especialmente útil para tareas de matemáticas, análisis lógico y resolución de problemas complejos. Si ya has trabajado con el modo de razonamiento de Gemini 3 Pro, la implementación en Gemma 4 sigue principios similares pero con un rendimiento superior.
Function calling nativo
Gemma 4 soporta llamada a funciones de forma nativa, sin necesidad de frameworks adicionales. El modelo puede generar llamadas a herramientas en formato JSON estructurado, lo que facilita la construcción de agentes autónomos que interactúan con APIs externas, bases de datos o servicios web.
Cómo escribir prompts para Gemma 4
Para obtener los mejores resultados con Gemma 4, es importante entender su formato de chat y las técnicas específicas de prompting que aprovechan sus capacidades.
Plantilla de chat
Gemma 4 utiliza un formato de turnos específico para las conversaciones. Este es el formato que debes seguir cuando interactúes directamente con el modelo (no a través de una API que lo abstraiga):
<start_of_turn>user
Tu pregunta o instrucción aquí<end_of_turn>
<start_of_turn>modelLos tokens <start_of_turn> y <end_of_turn> delimitan cada turno de la conversación. El prefijo user marca los mensajes del usuario y model indica dónde debe comenzar la respuesta del modelo. Si usas Gemma 4 a través de Hugging Face Transformers, Ollama o LM Studio, estos frameworks aplican la plantilla automáticamente.
Activar el modo de razonamiento
Para tareas que requieren análisis profundo, puedes activar el thinking mode añadiendo <|think|> al inicio de las instrucciones del sistema. El modelo dedicará ciclos de razonamiento interno antes de generar la respuesta visible.
Un detalle importante de la documentación oficial de Google: en conversaciones multi-turno, no debes incluir los bloques de pensamiento previos en el historial del chat. Solo conserva la respuesta final visible de cada turno anterior.
Prompts multimodales
Para prompts que incluyen imágenes, audio o vídeo, la documentación de Google recomienda colocar el contenido multimedia antes del texto en el prompt. Este orden mejora la capacidad del modelo para procesar y relacionar la información visual o auditiva con las instrucciones textuales.
Gemma 4 también permite controlar la cantidad de tokens dedicados a procesar cada imagen, con un rango configurable de 70 a 1120 tokens por imagen. Para tareas de clasificación general o captioning, un presupuesto bajo (70-280 tokens) es suficiente. Para OCR, lectura de texto pequeño o análisis de documentos, es preferible un presupuesto alto (560-1120 tokens).
Prompts para Gemma 4 listos para copiar y pegar
A continuación encontrarás prompts optimizados para Gemma 4, probados y listos para usar. Cada prompt aprovecha alguna capacidad específica del modelo y está orientado a casos de uso reales de marketing, e-commerce y gestión empresarial. Si buscas más inspiración para modelos de Google, consulta nuestra biblioteca completa de prompts para Gemini o pruébalos directamente en ilisai.
1. Análisis de texto con razonamiento profundo
Este prompt activa el thinking mode para que Gemma 4 analice un texto con razonamiento paso a paso antes de generar sus conclusiones.
Sistema: <|think|>
Eres un analista de estrategia empresarial con experiencia en mercados B2B.
Analiza el siguiente texto y genera un informe estructurado con:
1. Las 3 conclusiones más relevantes para la toma de decisiones.
2. Riesgos implícitos que el autor no menciona explícitamente.
3. Oportunidades que se derivan del análisis.
4. Una recomendación de acción concreta con horizonte temporal de 90 días.
Antes de responder, evalúa al menos dos interpretaciones alternativas del texto y justifica cuál consideras más sólida.
Texto a analizar:
[Pega aquí el texto, informe o artículo que quieras analizar]2. Auditoría visual de producto para e-commerce
Este prompt aprovecha las capacidades de visión de Gemma 4 para analizar fotografías de producto y creatividades de campaña. Ideal para equipos de marketing y e-commerce que quieran evaluar sus imágenes antes de publicarlas. Recuerda colocar la imagen antes del texto en el prompt.
[Adjunta la imagen de producto o creatividad aquí, antes del texto]
Eres un director de arte especializado en e-commerce y campañas de marketing digital.
Analiza esta imagen de producto considerando los siguientes criterios:
COMPOSICIÓN Y CALIDAD TÉCNICA
- Iluminación, enfoque, resolución y recorte. ¿Es apta para una ficha de producto en Shopify o Amazon?
- Fondo, sombras y consistencia con un catálogo profesional.
IMPACTO COMERCIAL
- ¿Transmite el valor del producto? ¿Genera confianza en el comprador?
- ¿Funcionaría como imagen principal en un anuncio de Instagram o Google Shopping?
- Compárala con los estándares habituales de marketplaces (Amazon, Zalando).
MEJORAS ACCIONABLES
- Lista 3 mejoras concretas ordenadas por impacto en conversión.
- Para cada mejora, indica si se puede resolver con edición (Photoshop, IA generativa) o requiere una nueva sesión fotográfica.
Formato de salida: secciones con encabezados y las mejoras como lista numerada.3. Asistente de atención al cliente con function calling
Gemma 4 soporta function calling nativo, lo que permite construir asistentes que consultan datos reales de tu negocio. Este prompt simula un agente de atención al cliente para una tienda online, útil para equipos que quieran automatizar respuestas sin perder calidad.
Tienes acceso a las siguientes herramientas de la tienda online:
1. consultar_pedido(numero_pedido: string) -> estado, fecha de envío, transportista, tracking
2. buscar_producto(nombre: string, talla: string) -> disponibilidad, precio, plazo de entrega
3. iniciar_devolucion(numero_pedido: string, motivo: string) -> número de devolución y etiqueta
Eres el asistente de atención al cliente de una tienda de moda online. Tu tono es cercano, profesional y resolutivo. Siempre ofreces una solución concreta.
Un cliente escribe: "Hola, pedí unas zapatillas la semana pasada (pedido #ES-29847) y todavía no me han llegado. Además quiero saber si tenéis la camiseta oversize negra en talla M."
Genera la secuencia de llamadas a herramientas necesarias en formato JSON. Después, simula respuestas realistas y redacta el mensaje completo que el cliente recibiría, incluyendo el enlace de tracking y la disponibilidad del producto.4. Estrategia de contenidos para marketing
Un prompt práctico para profesionales de marketing que quieran usar Gemma 4 como asistente estratégico. Aprovecha su capacidad de razonamiento para generar planes de contenido fundamentados.
Actúa como un estratega de contenidos senior especializado en SEO para el mercado español.
Contexto del negocio:
- Sector: [Tu sector, por ejemplo "software B2B para recursos humanos"]
- Público objetivo: [Describe a tu audiencia]
- Objetivo principal: [Por ejemplo "generar leads cualificados a través del blog"]
Genera un plan de contenidos para los próximos 30 días con:
1. 8 ideas de artículos, cada una con:
- Título optimizado para SEO (incluye la keyword principal)
- Keyword principal y 3 keywords secundarias
- Intención de búsqueda (informacional, transaccional, navegacional)
- Resumen del artículo en 2-3 frases
2. Una propuesta de estructura de enlazado interno entre los 8 artículos.
3. 3 ideas de contenido complementario (infografía, vídeo, newsletter) que refuercen el cluster temático.
Prioriza las ideas por potencial de tráfico orgánico y alineación con el objetivo de negocio.5. Comparativa de herramientas para tu negocio
Este prompt aprovecha la capacidad de Gemma 4 para generar análisis estructurados en formato de tabla. Perfecto para evaluar herramientas antes de contratar una suscripción.
Compara las siguientes herramientas de forma objetiva y estructurada:
Herramientas a comparar: [Lista tus opciones, por ejemplo "Mailchimp vs Brevo vs ActiveCampaign para email marketing de una PYME"]
Para cada opción, evalúa los siguientes criterios en una escala de 1 a 5:
- Facilidad de uso (sin perfil técnico)
- Relación calidad/precio para equipos pequeños (menos de 10 personas)
- Automatizaciones disponibles
- Integraciones con e-commerce (Shopify, WooCommerce)
- Soporte en español
- Capacidades de IA integradas
Presenta los resultados en una tabla con una fila por criterio y una columna por herramienta. Incluye una puntuación total ponderada donde relación calidad/precio y facilidad de uso pesan el doble.
Después de la tabla, escribe un párrafo de recomendación de no más de 100 palabras indicando qué herramienta elegir según el tamaño del equipo y el presupuesto mensual disponible.Dónde descargar y ejecutar Gemma 4
Gemma 4 está disponible en múltiples plataformas desde el día de su lanzamiento. La elección depende de tu caso de uso y del entorno donde planeas ejecutar el modelo.
Para uso local en tu ordenador:
- Ollama: la forma más rápida de ejecutar Gemma 4 en local. Un solo comando (
ollama run gemma4) descarga y ejecuta el modelo. Ideal para desarrolladores que quieren probar rápidamente. - LM Studio: interfaz gráfica para ejecutar modelos de IA en local. Soporta Gemma 4 con gestión visual de descargas, configuración de parámetros y chat integrado.
Para descarga directa de los pesos:
- Hugging Face: repositorio principal de distribución. Incluye las cinco variantes (con los checkpoints pre-entrenados e instruction-tuned del nuevo 12B), documentación técnica y compatibilidad con Transformers, bitsandbytes, PEFT y TRL.
- Kaggle: descarga alternativa con notebooks de ejemplo y acceso a competiciones que ya integran Gemma 4.
Para uso en la nube:
- Google AI Studio: playground web gratuito donde puedes probar las variantes 31B y 26B MoE sin instalación.
- Vertex AI: despliegue gestionado para producción empresarial con SLAs, monitorización y escalado automático.
Qué variante elegir según tu hardware
Si tienes un portátil sin GPU dedicada, E2B es tu mejor opción. Con una GPU de 8 GB de VRAM, E4B funciona bien para tareas de razonamiento. Con 16 GB de VRAM o memoria unificada (un MacBook actual o un portátil con GPU dedicada), la nueva 12B Unified es la elección por defecto si necesitas multimodalidad completa en local, mientras que la MoE (26B A4B) sigue ofreciendo la mejor relación rendimiento/coste para cargas de texto. Para la variante 31B Dense necesitarás 24 GB de VRAM o más.
Gemma 4 frente a Llama y otros modelos abiertos
Una de las preguntas más frecuentes al evaluar modelos open source es cómo se compara Gemma 4 con Llama de Meta y otros competidores. Esta tabla resume las diferencias principales, basada en datos publicados a fecha de abril de 2026.
| Característica | Gemma 4 31B | Llama 3.3 70B | Mistral 7B | Qwen 3.5 27B |
|---|---|---|---|---|
| Licencia | Apache 2.0 | Llama License (restricciones) | Apache 2.0 | Apache 2.0 |
| Parámetros | 30.700M | 70.000M | 7.200M | 27.000M |
| Multimodalidad | Texto + Imagen + Audio + Vídeo | Limitada | Texto + Imagen | Texto + Imagen |
| Contexto | 256K tokens | 128K tokens | 32K tokens | 128K tokens |
| GPQA Diamond | 84,3% | — | — | 85,8% |
| AIME 2026 | 89,2% | — | — | — |
| Function calling | Nativo | Parcial | Parcial | Sí |
| Audio nativo | Sí (E2B/E4B) | No | No | No |
| Variante MoE | Sí (26B A4B) | No | Sí (Mixtral) | Sí |
Gemma 4 destaca en varios frentes. Primero, consigue rendimiento comparable a Llama 3.3 70B con menos de la mitad de parámetros, lo que reduce drásticamente los requisitos de hardware. Segundo, es el único modelo open source de esta generación con soporte nativo de audio. Y tercero, la licencia Apache 2.0 ofrece más libertad comercial que la Llama License de Meta, que impone condiciones adicionales para empresas grandes.
Qwen 3.5 27B de Alibaba es su competidor más cercano en benchmarks de razonamiento (85,8% en GPQA frente al 84,3% de Gemma 4), pero carece de audio nativo y tiene una ventana de contexto más reducida. Para una comparativa entre modelos propietarios de alto rendimiento, consulta nuestro artículo sobre Claude Opus 4.6 vs GPT-5.3 Codex.
Preguntas frecuentes sobre Gemma 4
¿Es Gemma 4 gratis?
Sí. Gemma 4 se distribuye bajo licencia Apache 2.0, que permite uso personal y comercial sin coste de licencia. Puedes descargar los pesos del modelo, ejecutarlo en tu propia infraestructura y utilizarlo en productos comerciales sin restricciones. El único coste es el hardware o servicio cloud necesario para ejecutarlo.
¿Puedo ejecutar Gemma 4 en mi ordenador?
Depende de la variante. E2B (2.3B parámetros) funciona en ordenadores convencionales, incluso en un Raspberry Pi. E4B requiere un ordenador con al menos 8 GB de RAM. La nueva 12B Unified funciona en un portátil con 16 GB de VRAM o memoria unificada, y es la opción recomendada si quieres multimodalidad completa en local. Para las variantes grandes (26B MoE y 31B Dense) necesitarás una GPU dedicada con 16-24 GB de VRAM. La forma más sencilla de probarlo es instalar Ollama y ejecutar ollama run gemma4:e2b.
¿Cuál es la diferencia entre Gemma y Gemini?
Gemini es el modelo propietario de Google, accesible a través de API y de productos como Google AI Studio o la integración en Chrome. Gemma es la familia de modelos open source de Google, con pesos descargables que puedes ejecutar en tu propio hardware. Gemini tiende a ser más potente en sus variantes más grandes, pero Gemma 4 ofrece total control sobre el modelo, privacidad de datos y personalización sin depender de la nube de Google.
¿Soporta Gemma 4 el español?
Sí. Gemma 4 fue entrenado con datos en más de 140 idiomas, incluido el español. El rendimiento en español es competitivo con el de inglés para la mayoría de tareas, aunque como ocurre con todos los modelos de IA, el rendimiento en inglés tiende a ser ligeramente superior en benchmarks específicos.
¿Necesito GPU para usar Gemma 4?
Para las variantes E2B y E4B, no es estrictamente necesario. Funcionan en CPU, aunque la inferencia será más lenta. Para las variantes 26B y 31B, una GPU es prácticamente imprescindible para obtener velocidades de respuesta razonables. Si no tienes GPU, puedes usar Gemma 4 de forma gratuita en Google AI Studio.
¿Gemma 4 puede procesar vídeo?
Sí. Las variantes E2B y E4B soportan comprensión de vídeo con audio de forma nativa, y desde junio de 2026 la variante 12B Unified también procesa vídeo a 1 fotograma por segundo junto con su pista de audio, todo en local. Las variantes más grandes (26B y 31B) soportan procesamiento de imagen y texto, pero el soporte de audio y vídeo es más completo en las variantes edge y en la 12B.
Implementa modelos de IA open source en tu empresa
Te ayudamos a desplegar Gemma 4, diseñar prompts y construir flujos agénticos adaptados a tu negocio. Desde la selección del modelo hasta la integración en producción.
Sin compromiso · Respuesta en 24h
Conclusión
Gemma 4 representa un momento significativo para la IA open source. Con rendimiento que rivaliza con modelos propietarios de las mejores empresas del sector, licencia Apache 2.0 sin restricciones y capacidades multimodales completas (texto, imagen, audio y vídeo), Google ha eliminado varias de las barreras que tradicionalmente separaban los modelos abiertos de los propietarios.
Para desarrolladores y empresas, el abanico va desde la variante E2B para dispositivos edge hasta la 31B Dense para máximo rendimiento, pasando por la MoE (26B A4B) con 3.800 millones de parámetros activos y el nuevo 12B Unified, que desde junio de 2026 pone multimodalidad completa (texto, imagen, audio y vídeo) en cualquier portátil de 16 GB. Y los prompts que hemos incluido en esta guía son un punto de partida sólido para explorar lo que el modelo puede hacer.
Si ya trabajas con modelos de Google, Gemma 4 encaja naturalmente con tus flujos de trabajo existentes. Puedes complementar este artículo con nuestra guía de prompts para Gemini y nuestra colección de prompts para Nano Banana Pro para cubrir tanto texto como generación de imágenes con IA de Google.



![Prompts para Gemini: Guía y Biblioteca de Ejemplos [2026]](/images/blog/prompt-library-gemini/gemini-library-prompts-hero-1.webp)

![Prompts de Marketing E-commerce 2026: SEO, Ads y Email [Guía]](/images/blog/prompts-marketing-ecommerce-ia/prompts-para-ecommerce-blog-banner-1.webp)